So yesterday Michael in our team chatted through a client
Deteriorating Neurological condition. Signifcant VI - requires huge font Black on White background. Difficulty with Fine motor control but is literate. Tends to mouth words but not easily undersood.
She needs the letters so large we could use echo but we have to put it under apples magnifier - its not easy to setup.
Hmmmm. He is right. When we made pasco - you could do this. It allowed you to make the font so large it could show one letter at a time. But its not ideal (and that was super buggy). And Echo - we cant do that with. I need to fix it.. But..
Me: Do you need prediction?
Michael: Hmm yes - possibly
Me: Do you want next letter prediction:
Michael: Ideally.. yes
Hmmm. So what if we tear up the rule book (RICE scores does trigger this quite highly due to the rapidly deteriorating solution but really I dont like re-creating something..) and make something. Over the last 12 months I’ve made a ton of different stuff. All of these things were for a particular project but I’ve been careful to turn a lot of into libraries or standaline code. These “bricks” I always thought would be useful.. a JS word prediction system, a WorldAlphabets library and a TTS Wrapper in Node and Python…So we have the building blocks. What if I got a LLM to make this.. its pretty simple..
15 Minutes of prompting with Gemini (and then a bit of hacking - which took 4 times as long from me) I give you…
Its a React/Vite app (Gemini only does react but Im cool with that). And its leveraging our WorldAlphabets project and PPMPredictor. Note how it learns your own language and will improve over time.
Pretty happy with that. Still.. I really now need to go and fix Echo..
Quick demo of using the CoreMotionAPI you can get from Airpods to use as a headmouse. Annoyingly you can’t use just one airpod.. Or at least I cant figure out how..
I can’t be bothered to work on this any more as the use case is kind of 🤷 but hey! It does work! (Code)
I’m doing a ton of work on languages at the moment. This article is a good read why we don’t have diacritics in the English language. Love it.
After the Conquest, French took its place for centuries … But the period of French dominance left its mark on all aspects of the language … And, as Godwin found to his chagrin, it had a revolutionary impact on English spelling.
Last week we were honoured to win the Samantha Hunnisett Access Award at the CM Awards.
To be honest, I wasn’t expecting it. Most of my attention was on the big-ticket award of the evening — the Lifetime Achievement Award for Alli Gaskin. Alli was an awesome SLT colleague and friend, and she will be deeply missed. (If I did have any clue we were up for it I might have prepared a coherent speech and not drank two bottles of wine before hand. Apologies to all those who heard my garble on)
But fittingly, Alli also had a direct connection to Echo. While working at Lancasterian she supported a child whose communication needs weren’t being met by any existing AAC system. Echo bridged that gap. She immediately recognised its value and became one of its strongest champions. That connection made winning the award all the more meaningful.
Where It Started
Echo itself began initally as “Pasco”. Named by Euan Robertson (Phrase Auditory Scanning Communicator) we had it drafted for a while as we had around 6 or 7 end users who simply weren’t being supported by the auditory scanning options available. But then one of our clients Paul Pickford one day reached out to us. Paul said:
“I’m selling some stuff and I want to donate some money.”
Paul’s donation gave us the chance to act. Using our RICE framework, we prioritised building this tool — knowing it could have a meaningful impact.
The first version was hacked together quickly, but it worked. People like Darren, recovering from a brain stem stroke, were among the first to try it. From the start, Pasco (and then Echo) was shaped directly by the people who needed it.
A Chinese ICU Case
One case that has always stayed with me came from the early days, when Echo was still called Pasco and lived as a web app.
I met a woman in intensive care with significant visual impairment and minimal movement. But the bigger barrier? She was a native Chinese speaker, surrounded by English-speaking staff. Translation tools let staff tell her what was happening, but she had no way to respond.
We added multilingual support into Pasco: staff could cue in English, but she could output in Chinese. For the first time, she could communicate back. Her parents — also Chinese-only speakers — were in tears. I tried explaining with Google Translate, but it butchered my speech so badly I gave up and just demoed it. Seeing her finally communicate was enough to make me realise it was worth it.
Pasco Becomes Echo
At that stage, Pasco was still rough around the edges. The two-switch scanning had bugs that were difficult to fix. That’s when Gavin Henderson rewrote it in SwiftUI. (Side note: SwiftUI is a dream. I love it.)
That rewrite became Echo.
And then something amazing happened. I was at a conference in Croatia, getting ready to speak, when I noticed a talk being given in another language. I couldn’t follow the words at first, but eventually I realised what was being demonstrated on screen: Pasco. Somehow, it had been picked up and shared across borders, because we had made it open and multilingual. That moment drove home how far-reaching these tools can become when you don’t lock them away.
Open Source and Ongoing Challenges
Echo has always been about more than one app. It’s about showing what’s possible — and letting others build on it. That’s why we’ve kept it open source: 👉 github.com/acecentre…
We’ve also learned when to change direction. For example, we once had a clever “auditory splitting” feature — playing different parts of the audio to different devices. It worked, but it was fiddly. And ultimately, Apple’s iOS audio system won’t let us split audio streams the way we need. Until that changes, it’s not practical.
But the point remains: innovation often starts with finding a solution for one person. When shared openly, those solutions ripple outward and benefit many.
A Team Effort
So yes, the Access Award has Echo’s name on it. But really, it belongs to:
• Paul Pickford — whose donation started it all.
• Hossein Zoda — who built the first version (Pasco).
• Gavin Henderson — who rewrote it in SwiftUI and brought Echo to life.
• Michael Ritson (Ace Centre) — for deep input on visual impairment and access aspects.
• Charlie Danger — who once needed it working with a scroll wheel as input.
• And most of all, the end users — Darren, the client in ICU, and many others whose needs shaped the app.
It’s also for the wider Ace Centre team, who foster and curate ideas like this every day by working closely with individuals with disabilities.
Made a little tool to print alphabets (in alphabetical order, frequency, uppercase or lowercase) in a wide range of languages - and then keyboards for each of these languages.. for python or nodejs
I woke up this morning to see a ginger cat looking at me. Now I’m sure many of you are thinking “ ah that’s nice. you’ve got a new cat!” I haven’t got a cat. I have no idea how this cat got in my house.
Alright, gather ‘round, aspiring communication chefs! We’re about to embark on a culinary adventure – one where we cook up something genuinely useful for the world of Augmentative and Alternative Communication (AAC). This post dives into how we built tools to automatically correct sentences – specifically tackling tricky issues like typos and words mashed together without spaces. My goal here is to explain this in a way that makes sense, even if you’re not a tech wizard! I’ve gone with a cooking analogy. Now those of you know me know I love an analogy but also know that most of the time they are awful. This maybe one of them and I may take this a bit too far in this post..
What we did: We explored two main paths to auto-correction, like choosing between baking a cake from scratch or using a fancy pre-made mix:
Fine-tuning a Language Model: We took a small but powerful AI model (called t5-small) and taught it to correct noisy sentences. Think of this as perfecting a secret family recipe.
Developing Algorithmic Code: We also wrote specific computer code designed to fix spelling errors and add spaces where words were run together. This is more like mastering a basic, reliable cooking technique.
(Slightly less exciting but..well spoiler alert: the fastest and “best” using an online Large language model)
A quick note: If you’re looking for a current solution for an existing AAC system, Smartbox’s Grid3 “Fix Tool” is worth checking out. My work here was done before that tool existed, and it’s why you won’t see me rebuilding our model today!
Hold up. Before we continue if you do want to do this I recommend two things! 1. DONT RUN MY CODE but look at it by all means and be critical of it! 2. Let me know of improvements but 3. DON’T GET YOUR LLM TO MAKE THESE SCRIPTS FOR YOU. You’ll learn heaps more if you do it yourself. I say this with a recent history of geting LLM’s churning out code. Do the harder thing. Your brain will thank you.
The Core Ingredient: Why Automatic Correction Matters for AAC
AAC systems need to do a lot of things but ultimately for an end user they need to allow fast ways of getting your thoughts out from what you are trying to say - and understandable ones at at that. This isn’t just my hunch; it’s what we consistently hear from users, staff, and project feedback. The key term here is efficiency.
Sidenote: Efficiency in AAC isn’t just about the output. It could be speedier services, better quality support, or even device improvements like smarter input detection, but just to be clear for this post we are focusing on efficiency in output
The challenge often comes from “noisy” input – things like typing fast, or facing physical access challenges. Auto-correctionis our secret weapon for cleaning up this messy input and helping users get their message across more effectively.
Unlike prediction (where the system tries to guess what you’ll type next), auto-correction actively fixes mistakes afterthey’ve been made. Think about your phone – it’s constantly correcting your typos before you even see them. This happens seamlessly in the background, making it feel like your typing is perfect! (And you really notice it when it doesn’t work!) So, why isn’t this standard in AAC, where mistakes are equally common?
Approach 1: Building Algorithmic Correction Tools (Baking Our Own!)
When creating an AAC correction tool, it’s helpful to first understand the common “noisy” sentence types. These are the kinds of input issues we need to fix:
Ihaveaapaininmmydneck (No spaces and typos – a double whammy!)
I wanaat a cuupoof te pls (Double key presses – sticky keys, anyone?)
u want a oakey of cjeese please (Hitting nearby keys – positional errors)
can u brus my air (Missing letters/deletions – vanishing letters!)
Can you help me? Can you help me? (Repeated phrases – when a stored message goes wild!)
These sentences are typically short. While word prediction can help create perfect sentences, it often requires significant visual scanning and mental effort, which isn’t always ideal for AAC users.
Sidenote: We actually don’t know this for sure. There are some papers that document these types of errors but in short we don’t have a great grip on what is actually written by AAC users.. more on that later..
Tackling Words Without Spaces and Typos (Writingwitjoutspacesandtypos)
This is one of the trickiest problems. How do you separate words when they’re all jammed together?
Well turns out if you know some python code there is a clever library called wordsegment. This tool uses information about how common single words (“unigrams”) and two-word phrases (“bigrams”) are to figure out where words should be. Here’s an example:
It’s very effective! However, language is deeply personal. If wordsegment doesn’t know a user’s unique slang or abbreviations (like “biccie” for biscuit), it will struggle. For example, Iwouldlikeabicciewithmycuppatea might become ['i', 'would', 'like', 'a', 'bi', 'ccie', 'with', 'my', 'cuppa', 'tea'].
Truth is though, even with slight imperfections, the meaning is often still clear, especially if the user is communicating with a familiar partner. Sometimes, “good enough” is perfectly acceptable! In AAC, “co-construction” – where communication partners work together to understand – is super important. It happens all the time and you need to imagine any AAC system doesn’t work without it. We don’t always need to achieve perfect output.
Adding Our Secret Family Ingredients (Personalizing Algorithmic Tools with User Data!)
Imagine if we could incorporate a person’s actual vocabulary and common phrases into wordsegment’s data. This would significantly improve its accuracy for that specific user. We could take a user’s real-life language and use it to enhance the tool’s understanding, like using your grandma’s secret spice blend!
The wordsegment library allows for this kind of customization. When we did this work we even created specific “typo-heavy” two-word phrases based on real typing errors to make it smarter. This is a solid starting point, though capturing every personal nuance is challenging.
Another option is a “fuzzy” search approach (see this blogpost for some ideas on this). This method is light on memory and doesn’t require powerful computer graphics cards (GPUs), making it suitable for running directly on a device. While it might not be lightning-fast, it could be “quick enough” for many situations. However, it still faces challenges with acronyms, names, and highly unusual abbreviations.
Approach 2: Customizing Large Language Models (LLMs) (The Fancy Pre-Made Sauce)
What about the powerful Large Language Models (LLMs) like OpenAI’s GPT-3.5 Turbo? Let’s try wrapping our noisy sentences in an OpenAI GPT-3.5 Turbo API and see what happens:
The results are pretty nice. You can immediately see the benefit: users can focus on typing without being distracted by predictions. This could dramatically improve communication speed.
However, a key consideration with online LLMs is privacy. When communication data is sent to a cloud service, it raises questions about how that data is handled and to be fair some users - and providers of AAC are nervous of this. While some services offer opt-out options for data being used for model training, the notion of personal communication data residing in the cloud is something to address carefully.
It’s fair to say that whether “sending data to the cloud” is “unacceptable” is a nuanced point. Many people routinely use cloud services for sensitive personal information (like email, documents, or medical records), and some are increasingly comfortable sharing personal data with online AIs (is that a word now?). While some AAC users will undoubtedly prefer to keep all their communication entirely offline, others may not find it unacceptable, especially if there are clear privacy controls in place.
The primary privacy considerations often boil down to:
User Comfort and Perception: Users might be uncomfortable with the technology if they perceive the privacy risk to be greater than it actually is, or if they don’t trust the AAC providers to have robust privacy controls.
Provider Controls: The risk of poor privacy or security policies by an individual AAC provider, which could lead to chat data being logged, stored, or mishandled in the cloud.
Security Measures: The risk of security breaches providing unauthorized access to chat data flowing through APIs.
These risks can and should be mitigated through robust security measures and strong privacy controls, such as not logging or storing chats unnecessarily, and avoiding associating them with user-specific IDs in API calls. If an AAC provider implements these correctly, the benefits of advanced online LLM capabilities might outweigh the concerns for many users, even if it doesn’t allay everyone’s apprehension. But either way - it would be darned easier to explain to end users if data never left the device.
Therefore, for AAC, we need a solution that is:
Efficient: Quick to cook! Gets to you what meant accuratley and quickly
Privacy-focused: All in your kitchen, no external diners!
Training Our Own Language Model for Correction (The Holy Grail: Baking Our Own Language Model!)
Spoiler alert - This is what we want to make - note this video is all running on device
Building our own language model from scratch sounds daunting, but it’s more achievable than you might think! The fundamental ingredients are:
Data: A large collection of “noisy” sentences (like actual user input) alongside their perfectly “cleaned” versions. The more this data resembles real AAC communication, the better the model will perform.
Even More Data: Seriously, data is the most crucial ingredient.
Code: The “recipe” for teaching the model.
Computing Resources: Some time and a computer (preferably with a graphics card).
The biggest challenge is DATA. There’s very little publicly available “AAC user dialogue” data. What is “AAC-like text”? It’s a surprising gap in our industry’s research – we don’t have large datasets showing how people actually use AAC. Are stored phrases used all the time? What kind of unique language do users create? We’re often just guessing.
So, we have to “imagine” what AAC-like data looks like. Researchers like Keith Vertanen have made fantastic attempts with artificial datasets. We also believe “spoken” language datasets might be a good starting point, as AAC aims to enable “speaking” through a device. We looked at corpora like:
The problem? These are mostly perfectly transcribed texts, lacking the glorious typos and grammatical quirks our correction tool needs to learn from. We needed truly “noisy” input.
Injecting Noise: Making Our Data Deliberately Messy
To make our pristine datasets messy, we artificially injected errors using tools like nlpaug. While this creates synthetic noise, we also sought out real typos from sources like the TOEFL Spell dataset (essays by English language learners). For grammar correction, we also looked at datasets like JFLEG Data and subsets of C4-200M which contain grammatically incorrect sentences with their corrected versions.
Our Grand Baking Plan: Data Preparation:
Take each spoken text corpus.
Inject typos into the sentences and strip out common grammar elements (like commas and apostrophes, which AAC users often omit).
Create three versions of each sentence for training:
With typos.
With typos and compressed (no spaces).
The correct, clean version (but still without spaces, to train for de-compression).
Also, incorporate a grammar baseline layer using the grammar datasets.
We then used a “text-to-text transformer” model (specifically, the t5-small model) to learn from this data. This type of model is designed to take one text input and transform it into another, making it perfect for correction tasks. We chose t5-small because it’s lightweight and efficient enough to run on a device.
You can find the script for preparing the data here (you’ll need to download the BNC2014 corpus separately). The training process took several hours on a decent GPU. The resulting model is available on Hugging Face.
The Taste Test: How Did Our Bake Perform?
Let’s look at how our different correction techniques performed on a set of 39 test sentences (which contained both compression and typos):
Algorithmic Approach (Wordsegment + Spelling Engine): Took about 14 seconds to process the test sentences. This approach is surprisingly quick for what it does, and it has no memory issues. However, its major limitation is that it will fail if it encounters words not in its dictionary, or novel grammatical structures.
Online LLM (Azure/OpenAI GPT Turbo 16K): Took an astonishing 13 seconds! This speed, even with an external network call, is remarkable.
Now, for our custom-trained models:
Method
Accuracy (%)
Total Time (seconds)
Average Similarity
Inbuilt
0.0
17.32
0.93
GPT
55.56
13.29
0.92
Happy
28.95
N/A
N/A
Happy Base
13.16
N/A
N/A
Happy T5 Small
0.0
N/A
N/A
Happy C4 Small
0.0
46.90
0.81
Happy Will Small
28.95
N/A
N/A
HappyWill
N/A
24.67
0.93
Here are some example results comparing the incorrect sentence to the correct version and outputs from various models:
Incorrect Sentence
Correct Sentence
Output-Inbuilt
Output-GPT
Output-Happy
Output-HappyBase
Output-HappyT5
Output-HappyC4Small
Output-HappyWill
Feelingburntoutaftettodayhelp!
Feeling burnt out after today, help!
feeling burnt out aft et today help
Feeling burnt out after today, help!
Feeling burnt out today help!
Feelingburntoutaftettodayhelp!
Feelingburntoutaftettodayhelp!
Feelingburntoutaftettoday help!!
Feeling burnt out today help!
Guesswhosingleagain!
Guess who's single again!
guess who single again
Guess who’ssingle again!
Guess who single again!
Guesswhosingle again!
Grammatik: Guesswhosingleagain!
Guesswhosingleagain!!
Guess who single again!
Youwontyoubelievewhatjusthappened!
You won't you believe what just happened!
you wont you believe what just happened
You won't believe what just happened!
You want you believe what just happened!
You wouldn'tbelieve what just happened!
Youwontyoubelievewhatjusthappened!
Youwontyoubelievewhatjust happened!!
You want you believe what just happened!
Moviemarathonatmyplacethisweekend?
Movie marathon at my place this weekend?
movie marathon at my place this weekend
Movie marathon at my place this weekend?
Movie Marathon at my place this weekend?
Movie marathon at my place this weekend?
grammar Moviemarathonatmyplacethisweekend?
Moviemarathonatmyplacethis weekend?
Movie Marathon at my place this weekend?
Needstudymotivationanyideas?
Need study motivation, any ideas?
need study motivation any ideas
Need study motivation. Any ideas?
Need study motivation any ideas!
Need study motivationanyideas?
Needstudymotivationanyideas?
Needstudymotivationanyideas?
Need study motivation any ideas!
Sostressedaboutthispresentation!
So stressed about this presentation!
so stressed about this presentation
So stressed about this presentation!
So stressed about this presentation!
So stressed about this presentation!
Sostressedaboutthispresentation!
Sostressedaboutthispresentation!!
So stressed about this presentation!
Finallyfinishedthatbookyourecommended!
Finally finished that book you recommended!
finally finished that book you recommended
Finally finished that book you recommended!
Finally finished that book you're recommended!
Finally finished that book yourecommended!
Finalfinishedthatbookyourecommended!
Finally finished that bookyourecommended!!
Finally finished that book you're recommended!
Our custom-trained model (HappyWill) actually outperformed GPT in terms of average similarity! While its total time was longer because we ran it on a small cloud machine, it would be much faster on a local device – and, crucially, it keeps all data private.
However, it’s important to note the “inbuilt” algorithmic technique (the Wordsegment one). While its “accuracy” (meaning, how often it perfectly matched the exact expected output) was low for our specific test, its output was surprisingly readable, and it has no privacy or significant memory concerns.
You can try the inbuilt algorithmic correction yourself for a short while via our API:
So, the next crucial step in our culinary journey? We need to hunt down, or create, an even richer, noisier, and more authentic corpus of data. The quest for the perfect “ingredients” continues!
(Oh dear.. This cooking analogy really went too far… I do apologise)
Key Takeaways
From this project, we’ve identified a few critical points for developing communication tools:
Understanding Language Models for Correction (How to Broadly Make a Language Model for Correction): We’ve shown how a custom, fine-tuned language model (like t5-small) can be developed to correct complex errors while keeping user data private and enabling on-device processing. It’s about tailoring the perfect sauce to your needs.
Algorithmic Approaches Can Be Effective (Algorithmic Approaches May Be As Good In Some Circumstances): For specific problems, like adding spaces or basic spelling, simpler algorithmic approaches can be surprisingly readable and efficient, offering a viable alternative to complex AI models, especially when novel input isn’t a primary concern. This highlights the importance of matching the tool to the specific type of communication challenge – sometimes, a good old stew is just what you need!
The Need to Understand User Corpora Better (We Need to Understand Better Users Own Corpora): Regardless of the approach, the effectiveness of any correction tool is heavily dependent on the training data. There’s a significant need for more authentic, “noisy” datasets reflecting how AAC users actually communicate. Truly understanding users’ unique vocabulary and communication patterns – their personal “flavor profiles” – is essential for building the most effective tools.
AI doesnt hallucinate. Its not a bloody person. Lets be clear - it get its wrong. If we want to anthropomorphise our technology we could say “Poor AI it got confused” or “That shit. It just lied”. But no. Its a statistical inference machine. It got it wrong.
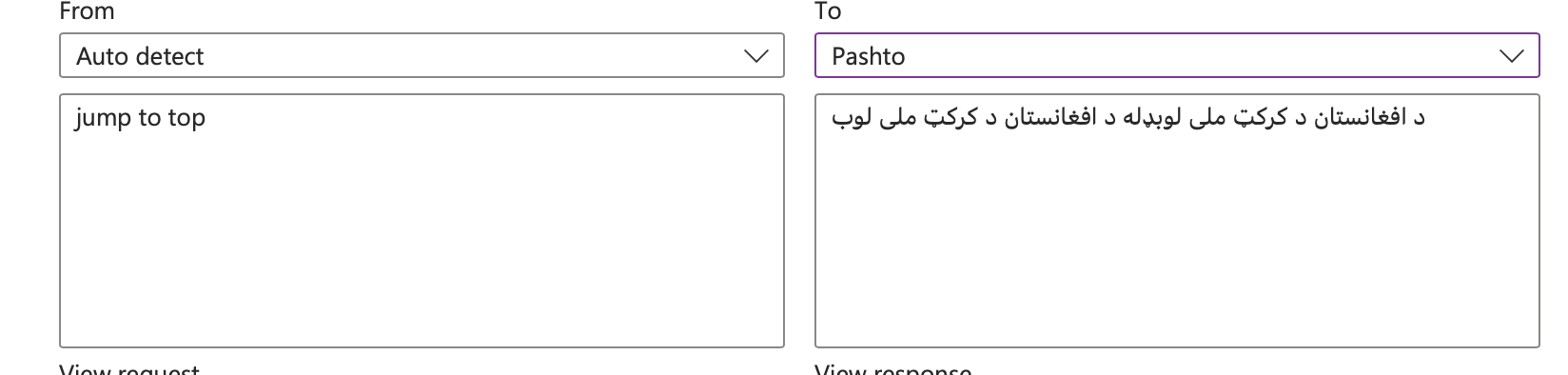
Does anyone know how I submit a bug report to Microsoft Azure Team on their translation tool? I keep coming across problems - like Eng->Pashto - all strings are “Afghanistan National Cricket team”. Is nobody checking these lang pairs? Seen similar problems in Kurdish and other langs..
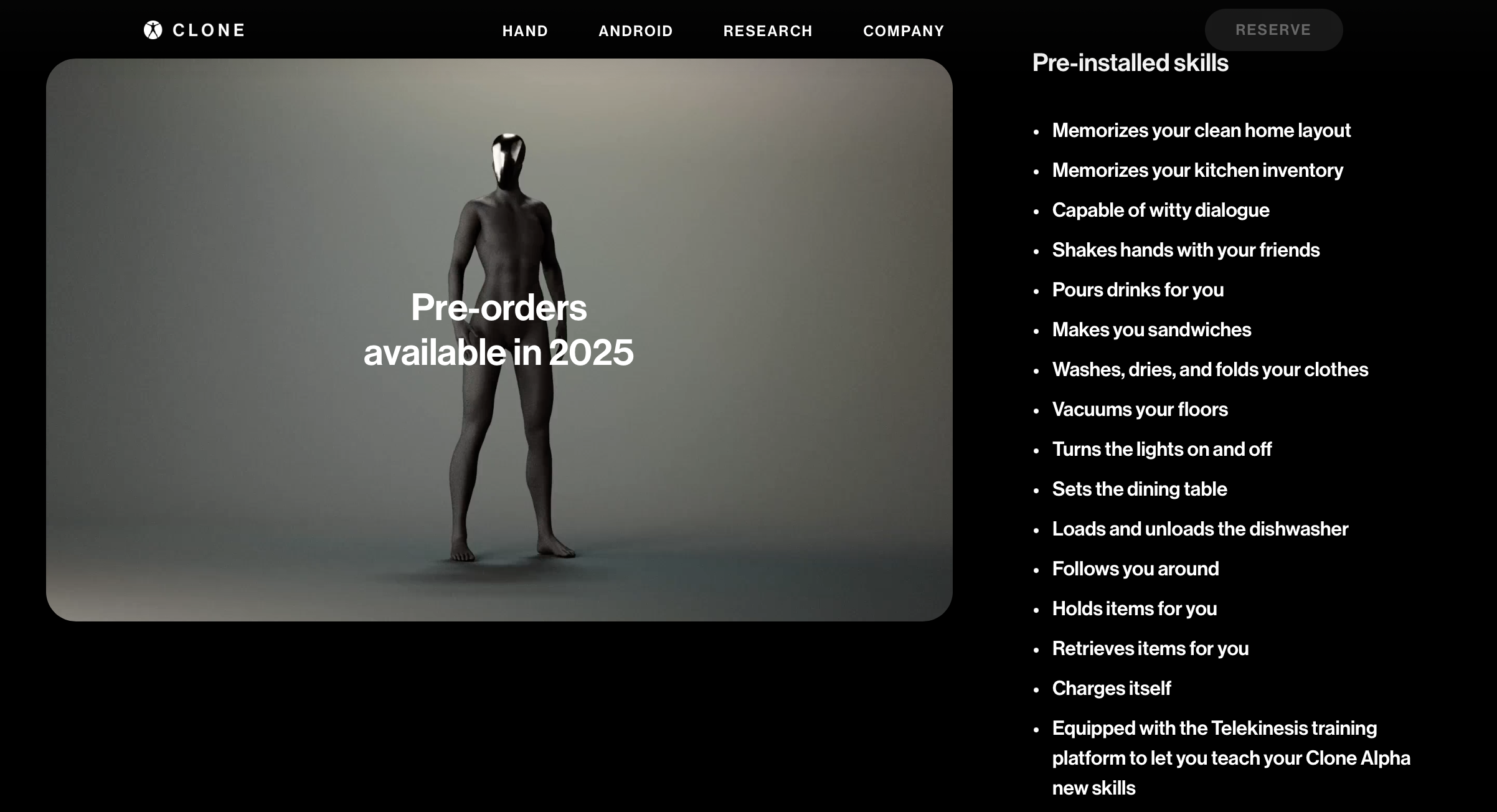
Who the hell would be crazy enough to buy this? Shaking hands with my friends? How did that reach the top of the pile for v1 must have features? I’m more concerned that this would “Memorizes your kitchen inventory..”.. “Memorizes your clean home layout”. Go on, cyber overlords. Take everything.
I’ve made ANOTHER tool to load up your env vars in a terminal. Why? Because I had a mare getting direnv to work on my specific Windows machine. It was really due to the way our office locked down the way a users $PROFILE works - that is it puts everything on OneDrive and there was a ton of admin issues getting it all working correctly. So, stupidly, rather than fixing that properly I found it (more fun?) to build a cross platform simplifed direnv tool.
This is common syntax for dotenv and direnv, but it won’t work as-is across all terminals. You need a tool to convert it properly for your shell. direnv IS your tool of choice, but if you like me, you cant just get it working - or the numerous other tools out there like it and you spend too many hours fiddling to get them to work (because you have a Windows machine which has really tight admin rights on it) you could try this little tool I’ve made..
Install on Mac/Linux
brew tap willwade/envloade
brew install willwade/envloader/envloader
then in a terminal you can run envloader and press enter. It will find a .env or .envrc and convert the lines appropriately for your shell.
e.g.
envloader
Make your life a bit easier and write an alias in your env - details here
I haven’t gone to town building lots of neat integration tricks - and unlike direnv it DOESN’T autoload on entering/exiting a directory. But running ‘envload’ now does the trick just fine for me. Maybe for you too.
So we built this aacprocessors library. Intention was to read and manipulate any AAC software. Its not ideal but just made a new method just for the grid right now.
def replace_cell_with_xml(
self,
gridset_path: str,
target_caption: Optional[str],
target_action: Optional[str],
new_content_xml: str,
output_path: str,
) -> None:
"""Replace a cell's content with a new XML fragment across the gridset.
Args:
gridset_path (str): Path to the original gridset file.
target_caption (Optional[str]): Caption of the button to replace.
target_action (Optional[str]): Action command of the button to replace.
new_content_xml (str): New XML content for the cell.
output_path (str): Path to save the modified gridset.
"""
So search for a action or a cell label and it will replace all buttons tin the gridset with the xml of the button you replace it with.
Really this needs more thought and a way of mking this across all AAC file types. I’m thinking a ‘replace_cell_with_raw’ method for sql or filebased systems. Its quite a bit different for sqlite systems though as they abstract the button logic from the content. Needs more thought
If anyone out there is a python dev - and wanting TTS support in theri code - I’d love someone to help roadtest this python library. I think its probably the most extensive TTS wrapper accessing pretty much every online and offline TTS engine… in a nice unified way.. AVSynth on MacOS is what I really want testing due to the mad way we create a swift bridge.. I feel its going to break.. just how and when?!
Adam did this marvellous reprint of the poppy mini trackball for a client needing a chin controlled trackball. This modification stops it falling out. It’s a win as the designs are all open source. @PKL@mastodon.social
Been working with Sherpa-Onnx TTS a lot over the last year. It’s a nice project to make a onnx runtime for lots of different languages and interfaces. Just whipped together a Gradio demo to show all the voices and hear them - most notably MMS Onnx models Sherpa-Onnx Demo
Monkey Management ideas aren’t new (eg see this which quotes it as being from 1975). It’s basically describing the problem of how unsolved problems of employees are pushed upwards causing the “monkey” to jump on a manager’s back. This increases workload for a manager and makes focus difficult. This piece nicely discusses the issue in the view of Product management.
Despite the complexity, monkey ownership continues for Product. It is your circus, but not your job to train monkeys.
Monkey management is effective when there is organizational complexity. It has two critical benefits. The first is time management and the second is creating high agency staff who are able to deal with problems autonomously.
If you understand whose back the monkey is on, you can understand the art of time management and delegation.
The reason monkey keeps jumping around is because there are ZERO directly responsible owners of the delivery of the cross-functional outcome for the business.
In my company, we have PM, Sr. PM, Director of Product, VP of product - interfacing with Designer, Sr. Designer, Design manager, Sr. Design manager, director of design - interfacing with Eng 2, Sr Eng, Eng manager, Sr Eng manager, Eng director, Sr. Eng director, Eng VP.
Nobody can tell who owns the final decisions, decisions cannot be bubbled up, every management chain is only focused on their own goals. There is no decision-making structure at all. Inevitably projects get delayed or there are unaccounted issues. Then each management chain stack ranks their reports for not achieving goals - never once accepting that the empire structure never made any decisions when it was necessary.
The empire structure has to go. It is dysfunctional, doesn’t work, and only causes grief to everyone involved. Tasks are unnecessarily hard. It is easy to do. Just make your highest paid people directly responsible for outcomes. Give them the freedom to pull people from various org functions to get a project to success.
The problem with permission is that you are implicitly asking someone else to take some responsibility for your decision. You aren’t inviting them to participate in its success — permission is hardly seen as a value adding behavior — but if it goes wrong you might end up involving them in the failure: “Hey, I asked that team and they said it was fine.
and
Advice, on the other hand, is easy. “Hey, I was thinking about doing X, what advice would you give me on that?” In this instance you are showing a lot of respect to the person you are asking but not saddling them with responsibility because the decision is still on you.
Its a great read. Whats interesting though is what happens when it goes wrong. From HN
“…and when someone asks for your permission (probably because you’re in the person’s management chain), one response could be: “you don’t need my permission, if you think it is a good idea after getting input, go for it. If it turns out to be a bad idea, share your learnings so we don’t repeat the same mistake.””
Published our py3-tts-wrapper python library finally this week. Should power a lot of funky things. Supports all the major TTS engines online and new ones offline. Use alongside this app to see what voices are available (API here)
Sometimes you have to do the hard graft as nobody else wants to. huggingface.co/willwade/… - all ONNX models of the Meta MMS Text to Speech models (code: github.com/willwade/… - and all suitable for sherpa-onnx)